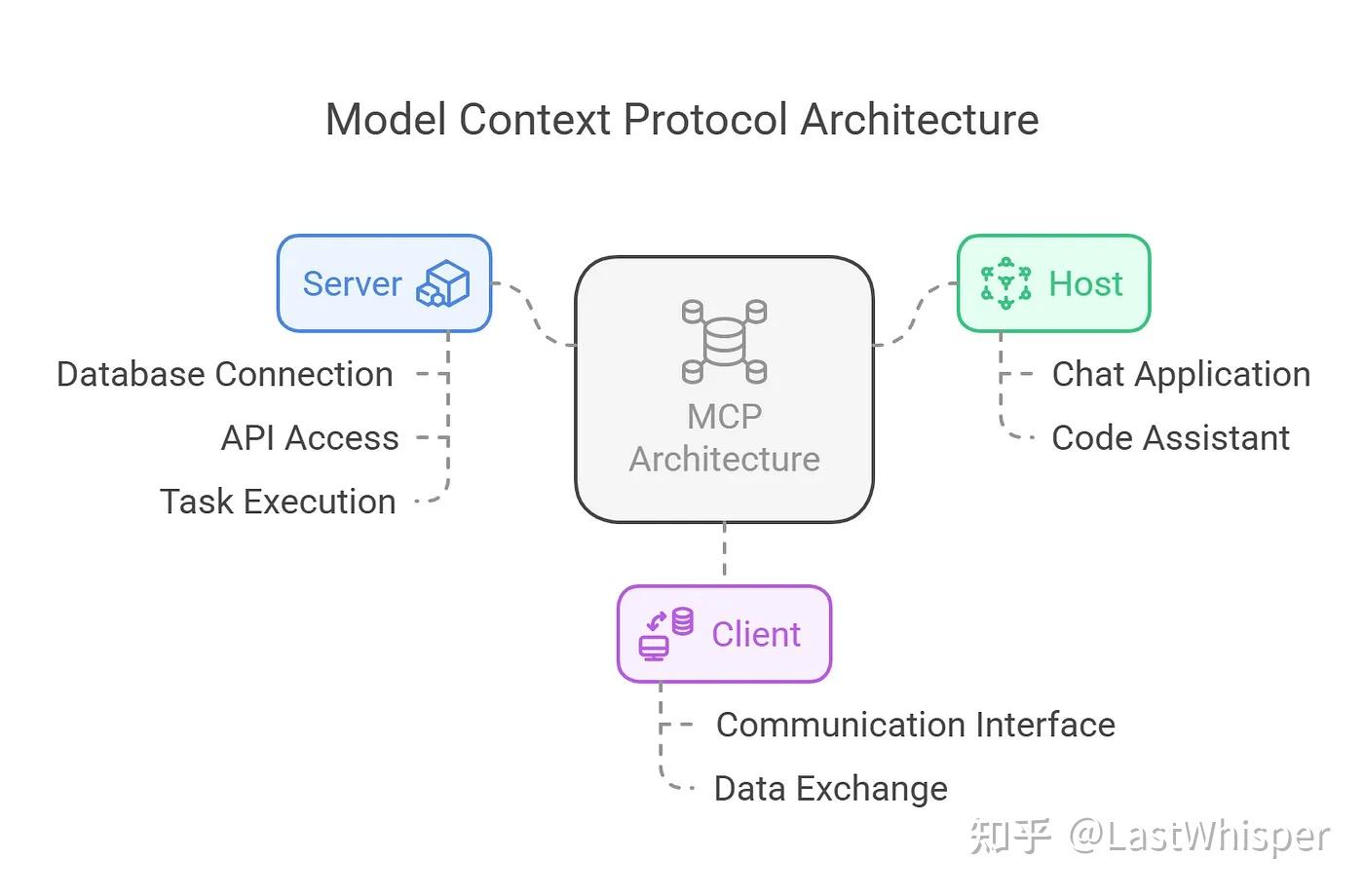
MCP vs Function Calling
自从大语言模型(LLM)横空出世以来,如何将 LLM 与现有商业系统有效结合、让其真正赋能各类业务,已成为当前最热门的研究方向之一。
Function Calling 和 Model Context Protocol(模型上下文协议,MCP)是实现这种让 LLM 与外部系统进行交互的两种关键技术概念。然而二者在概念上有所重叠,很多人并不能讲出两种概念的区别与联系。
Function Calling
外部系统通常会以函数(function)的形式进行封装,LLM 通过函数调用(function calling)可以实现与外部系统的交互。
工具(Tool)
Function 这个术语实际上已经废弃了,取而代之的是 Tool。Tool 泛指指一切 LLM 能够调用的外部工具。Tool 相比 function 要更加广义,只不过目前的 tool 只有 function calling 这一种形式,因此为了文章方便理解,就这里认为 function 与 tool 是等价的。
Function Calling 具体指的是 LLM 根据用户的自然语言输入,自主决定调用哪些函数,并进行格式化的函数调用的能力。一般的过程如下:
-
将用户的自然语言输入与已有函数的描述作为输入参数传给 LLM;
-
LLM 结合输入参数,决定调用哪些函数,并指明必要参数(如函数的入参),进行格式化(如 JSON、XML 格式)的输出;
-
用户端接收到 LLM 格式化的函数调用后,对本地的函数进行调用,得到结果;
-
将得到的函数结果传给 LLM,使得 LLM 有了所需的上下文信息。
Function Calling 时序图(来自 OpenAI 开发者文档)
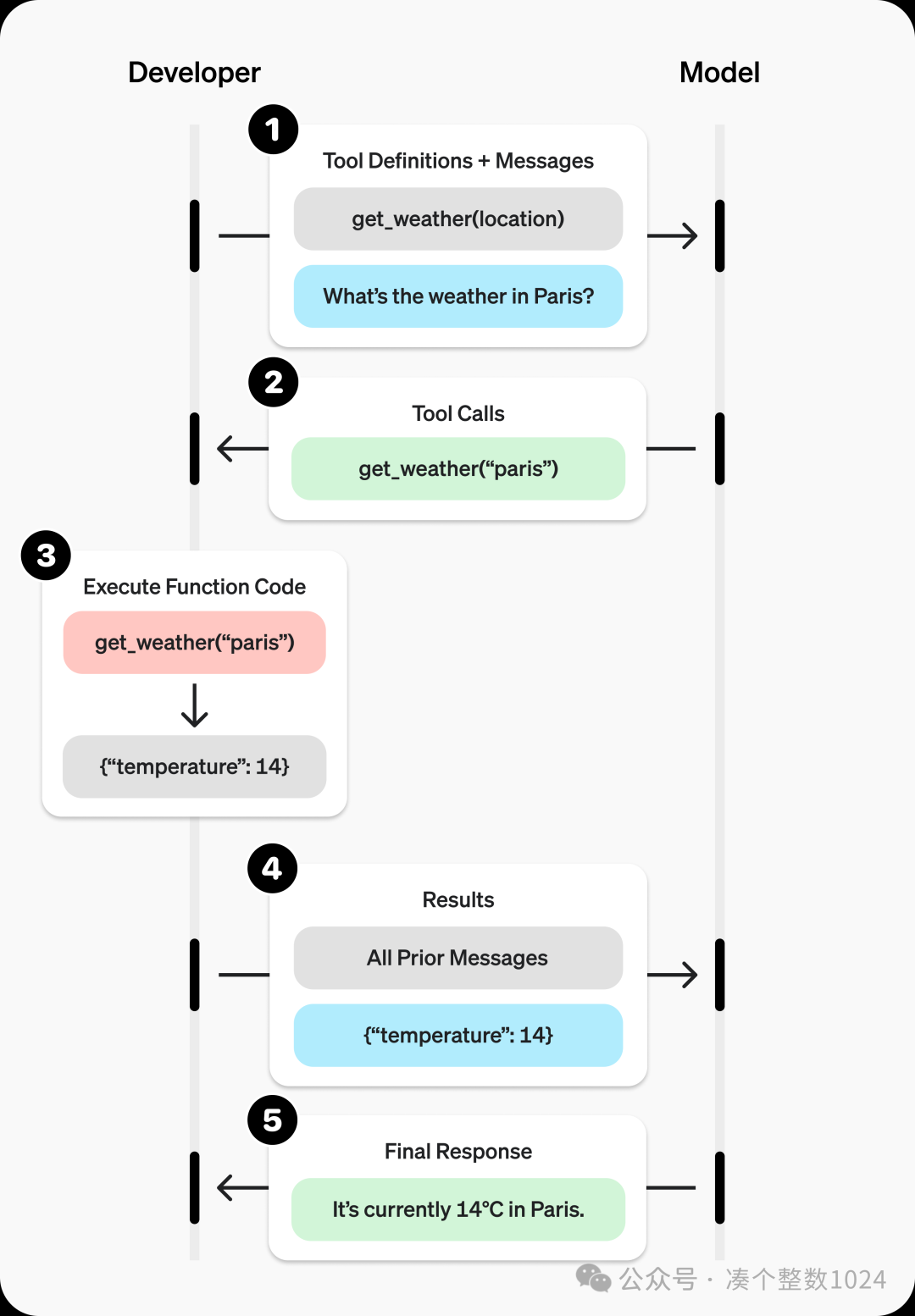
Function Calling 实际上强调的是 LLM 本身的能力,一些经过特殊训练或调优的 LLM 能够根据用户的自然语言输入决定使用哪些函数,并按约定的格式表达出函数的调用。这里所描述的 “格式”,不同 LLM 提供商之间是可能有差异的。
假设我们有个叫做 get_weather 的 function,入参为地点 location,不同 LLM 提供商会给出不同的 function calling 格式:
OpenAI ChatGPT:
{
"type": "function_call",
"id": "fc_12345xyz",
"call_id": "call_12345xyz",
"name": "get_weather",
"arguments": "{\"location\": \"Shanghai\"}"
}Anthropic Claude:
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "<thinking>To answer this question, I will: 1. Use the get_weather tool to get the current weather in San Francisco. 2. Use the get_time tool to get the current time in the America/Los_Angeles timezone, which covers San Francisco, CA.</thinking>"
},
{
"type": "tool_use",
"id": "toolu_01A09q90qw90lq917835lq9",
"name": "get_weather",
"input": {"location": "Shanghai"}
}
]
}Google Gemini:
{
"functionCall": {
"name": "get_weather",
"args": {
"location": "Shanghai"
}
}
}Model Context Protocol (MCP)
当 LLM 发起了一个 function calling 后,这个 calling 最终会需要外部系统进行执行,而 MCP 正是提供了一个通用的协议框架调用外部系统执行这个 function calling。本文不会对 MCP 的概念进行具体说明,假设读者已了解。
带入到上文所述的 function calling 步骤,MCP 实际上规范的就是步骤 3,也就是函数的具体执行过程。无论 LLM 返回的 function calling 是什么样子的格式,在步骤 3 时都需要转换成 MCP 所规定的 API 数据结构(这一步转换应该是 MCP host 需要做的),并需要 LLM 用户侧按照 MCP 的规范进行响应的处理。例如对于上文的 get_weather ,MCP server 接收到的请求结构必须是这样的 JSON-RPC:
{
"jsonrpc": "2.0",
"id": 129,
"method": "tools/call",
"params": {
"name": "get_weather",
"arguments": {
"location": "Shanghai"
}
}
}MCP client 接收到的响应则是类似于这样的 JSON-RPC:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"content": [
{
"type": "text",
"text": "Current weather in Shanghai:\nTemperature: 12°C\nConditions: Partly cloudy"
}
],
"isError":false
}
}MCP 标准化了 LLM 应用与外部系统的以下交互过程:
-
动态地提供对可用函数的标准化的描述(比如通过 tools/list API);
-
标准化对外部系统的调用与结果的处理(MCP 规范了 MCP server 需要有哪些 API 能力,以及 API 的请求/相应数据结构)。
如果没有 MCP 这样的协议规范,不同团队的 LLM 应用需要:
-
自行维护可用函数列表;
-
外部系统的接入需要进行针对适配,不具有通用性。
现在只要一个 LLM 应用有 MCP client 的功能,那么它就一定能支持接入任何具有 MCP server 功能的外部系统,且不需要额外的适配成本,MCP 很好地构建了 LLM 应用的大生态。
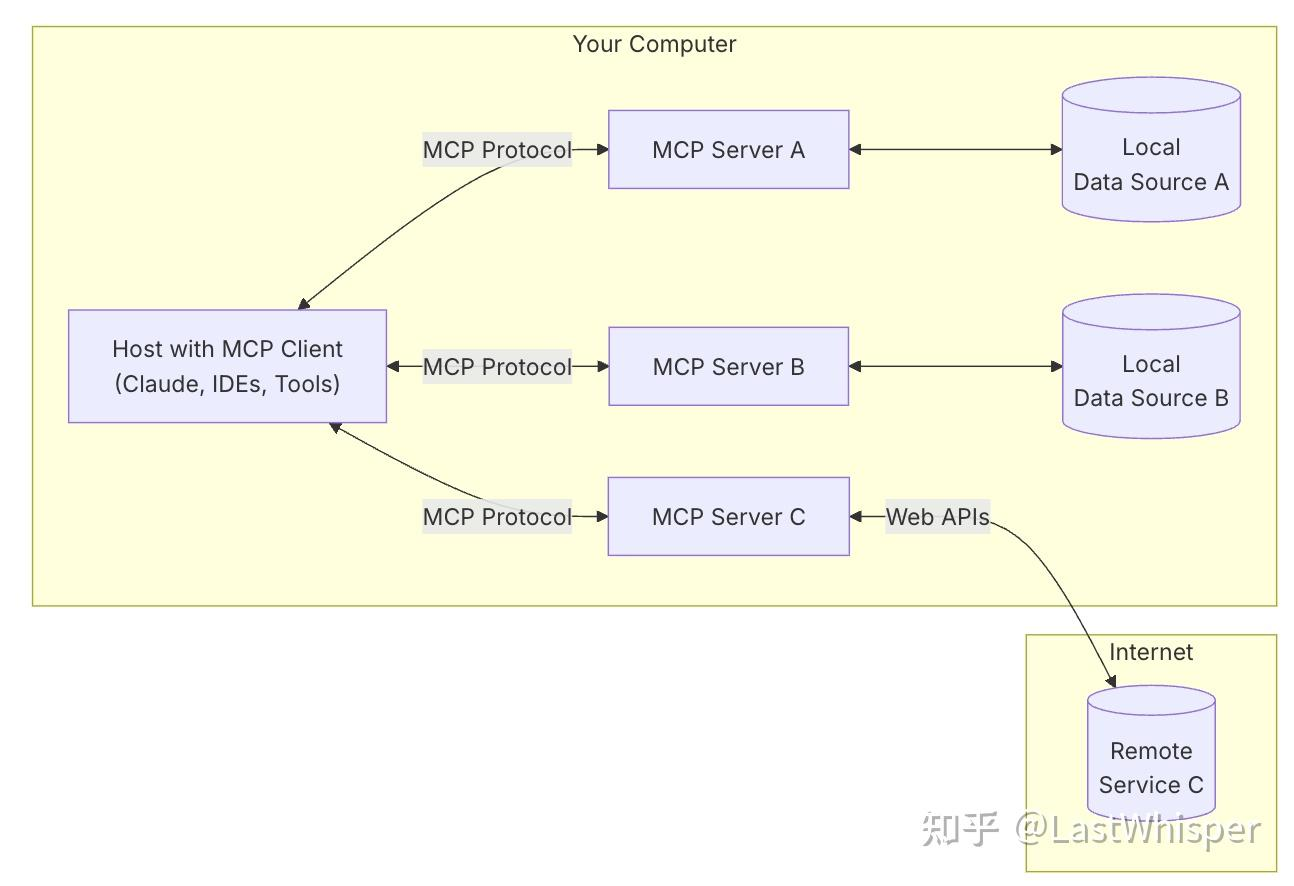 MCP 由三个核心组件构成:Host、Client 和 Server。让我们通过一个实际场景来理解这些组件如何协同工作:
MCP 由三个核心组件构成:Host、Client 和 Server。让我们通过一个实际场景来理解这些组件如何协同工作:
假设你正在使用 Claude Desktop (Host) 询问:“我桌面上有哪些文档?”
- Host:Claude Desktop 作为 Host,负责接收你的提问并与 Claude 模型交互。
- Client:当 Claude 模型决定需要访问你的文件系统时,Host 中内置的 MCP Client 会被激活。这个 Client 负责与适当的 MCP Server 建立连接。
- Server:在这个例子中,文件系统 MCP Server 会被调用。它负责执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
整个流程是这样的:你的问题 → Claude Desktop(Host) → Claude 模型 → 需要文件信息 → MCP Client 连接 → 文件系统 MCP Server → 执行操作 → 返回结果 → Claude 生成回答 → 显示在 Claude Desktop 上。
这种架构设计使得 Claude 可以在不同场景下灵活调用各种工具和数据源,而开发者只需专注于开发对应的 MCP Server,无需关心 Host 和 Client 的实现细节。